Geometric Shape Understanding
|
|
3D Deep Learning for Shape Abstraction
Deep learning approaches have started simplifying several traditional computer vision tasks to be conducted accurately and efficiently. Although recognition, detection, and segmentation tasks are heavily explored by deep learning approaches, deep learning met shape and geometry understanding with a delay. We explore different shape representations for several deep learning tasks in 2D and 3D domains for geometric shape understanding, especially to condense global shape information into compact representations. |
|
Guided Proceduralization
We describe a guided proceduralization framework that optimizes geometry processing on architectural input models to extract target grammars. We bridge the gap between creation and generation by converting existing manually modeled architecture to procedurally editable parametrized models, and carrying the guidance to procedural domain by letting the user define the target representation. Additionally, we propose various applications such as guided completion of point clouds, controllable 3D city modeling, and other benefits of procedural modeling. |

|
Near-convex Decomposition for Efficient 3D Printing
We introduce a novel divide-and-conquer approach for 3D printing, which provides automatic decomposition and configuration of an input object into print-ready components. Our method improves 3D printing by reducing material consumption, decreasing printing time, and improving fidelity of printed models. An input object is decomposed into a set of components obtained by a near-convex segmentation that minimizes an energy function. Then the configuration phase provides a robust algorithm to pack the components for an efficient print job. |

|
Coupled Segmentation and Similarity Detection
Recent shape retrieval and interactive modeling algorithms enable the re-use of existing models in many applications. However, most of those techniques require a pre-labeled model with some semantic information. We introduce a fully automatic approach to simultaneously segment and detect similarities within an existing 3D architectural model. Our framework approaches the segmentation problem as a weighted minimum set cover over an input triangle soup, and maximizes the repetition of similar segments to find a best set of unique component types and instances. |
Geospatial Machine Learning
|
DeepGlobe
We observed that satellite imagery is a rich and structured source of information, yet it is less investigated than everyday images by computer vision researchers. However, bridging modern computer vision with remote sensing data analysis could have critical impact to the way we understand our environment and lead to major breakthroughs in global urban planning or climate change research. We aim to improve and evaluate state-of-the-art satellite image understanding approaches, which can hopefully serve as reference benchmarks for future research in the same topic. |

|
|
Generative Street Addresses
Currently, 75% of the world’s roads lack adequate street addressing systems. We propose a generative address design that maps the globe in accordance with streets. Our algorithm starts with extracting roads from satellite imagery by utilizing deep learning. Then, it uniquely labels the regions, roads, and structures using some graph- and proximity-based algorithms. We also extend our addressing scheme to (i) cover inaccessible areas following similar design principles; (ii) be inclusive and flexible for changes on the ground; and (iii) lead as a pioneer for a unified street-based global geodatabase. |
|
Modeling & Reconstruction
|
|
The Future of Filmmaking: AI + Volumetric Reconstruction at Intel Studios
The world’s largest volumetric capture studio opens its doors for a behind the scenes tour of Intel Studios! This talk encapsulates our pipeline to entangle technical challenges of 10X scale in time and space when filming with over a hundred 8K cameras; introduces the stage's capabilities over traditional filmmaking for artists, producers, and researchers; and showcases sneak peeks of our upcoming productions such as immersive VR experiences and mobile AR apps. |
|
|
3D Reconstruction from Large Unstructured Photo Collections
Can we utilize large unstructured photo collections for 3D reconstruction of landmarks? How can we organize such images without geotags? What about filters, manipulations, partial visibility, humans in front of structures? Can we reconstruct time-varying models as day-night, summer-winter, and so on? Can we utilize deep learning approaches beyond image classification to solve the mentioned ambiguities? And finally, how can we reconstruct at scale to create a 3D map of the world? This project aims to propose methods and improvements to solve these challenges in large scale reconstruction. |

|
Proceduralization of Point Clouds
We tackle the problem of point cloud completion and editing and we approach it via inverse procedural modeling. Contrary to the previous work, our approach operates directly on the point cloud without an intermediate triangulation. Our approach consists of 1) semi-automatic segmentation with segment comparison and template matching, 2) a consensus-based voting schema and a pattern extraction algorithm, and 3) an interactive procedural editing tool where the user can create new point clouds in the same style. |
|
|
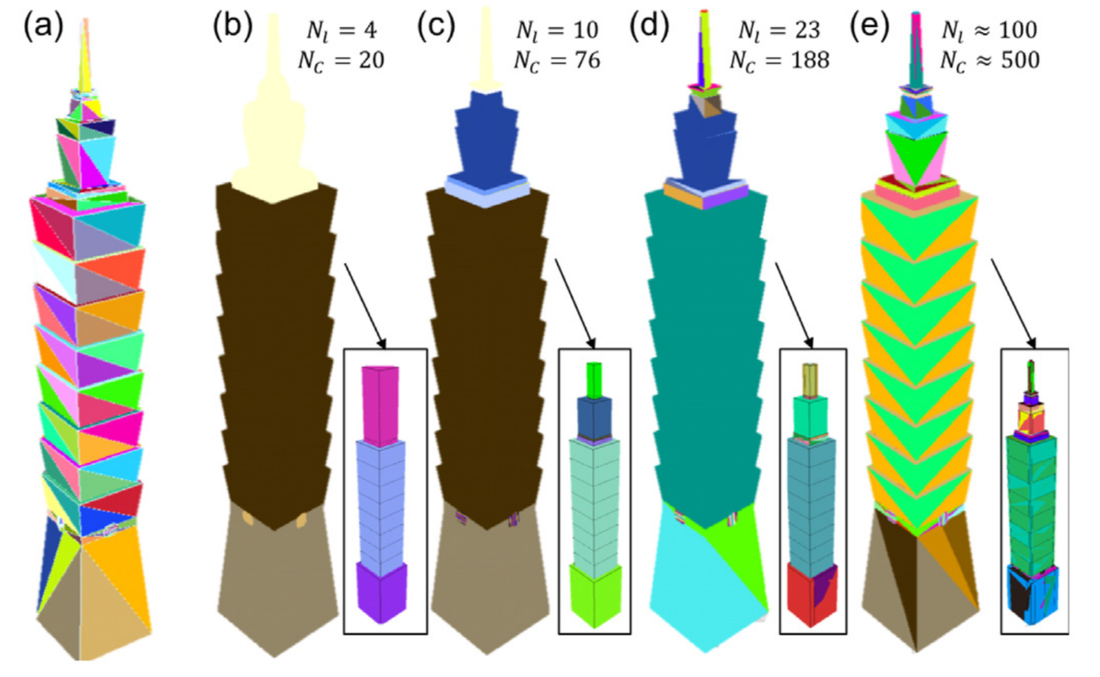
Structure-aware Procedural Editing of Architecture
We introduce an automatic approach that generates a compact, efficient, and re-usable procedural representation of a polygonal 3D architectural model. This representation is then used for structure-aware editing and synthesis of new geometric models that resemble the original. Our framework captures the pattern hierarchy of the input model into a split tree data representation. A context-free split grammar, supporting a hierarchical nesting of procedural rules, is extracted from the tree, which establishes the base of our interactive procedural editing engine. We show the application of our approach to a variety of architectural structures obtained by procedurally editing web-sourced models. |
Urban Proceduralization at Scale
We present a framework for the conversion of existing 3D unstructured urban models into a compact procedural representation that enables model synthesis, querying, and simplification of large urban areas. During the de-instancing phase, a dissimilarity-based clustering is performed to obtain a set of building components and component types. During the proceduralization phase, the components are arranged into a context-free grammar, which can be directly edited or interactively manipulated. We applied our approach to convert several large city models, with up to 19,000 building components spanning over 180 km squares.
We present a framework for the conversion of existing 3D unstructured urban models into a compact procedural representation that enables model synthesis, querying, and simplification of large urban areas. During the de-instancing phase, a dissimilarity-based clustering is performed to obtain a set of building components and component types. During the proceduralization phase, the components are arranged into a context-free grammar, which can be directly edited or interactively manipulated. We applied our approach to convert several large city models, with up to 19,000 building components spanning over 180 km squares.

|
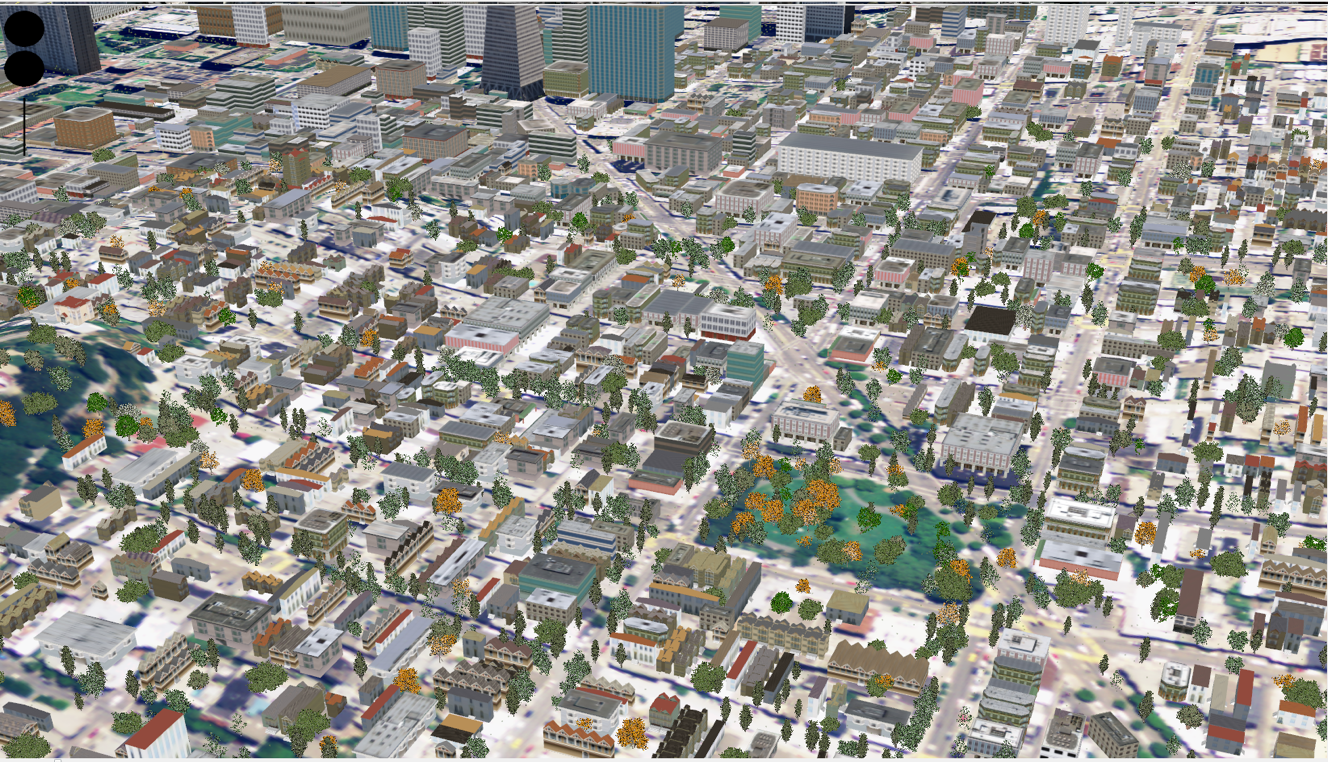
UrbanVision
UrbanVision is an open source software system for visualizing alternative land use and transportation scenarios at scales ranging from large metropolitan areas to individual neighborhoods. The motivation behind this system to fill the gap between the outputs of existing land use and transportation models and the automatic generation of 3D urban models and visualizations. The simulation includes over 60 procedural model types, pedestrian and traffic animations, roads, sidewalks, and vegetation models. |
Volumetric Reconstruction & Graph Cuts
We present an approach to automatically reconstruct buildings densely spanning a large urban area. Our method takes as input calibrated aerial images and available GIS meta-data. Our computational pipeline computes a per-building 2.5D volumetric reconstruction by exploiting photo-consistency where it is highly sampled among the aerial images. Our building surface graph cut method overcomes errors of occlusion, geometry, and calibration in order to stitch together aerial images and yield a visually coherent texture-mapped result. Our comparisons show similar quality to the manually modeled buildings of Google Earth, and show improvements over naive texture mapping and over space-carving methods.
We present an approach to automatically reconstruct buildings densely spanning a large urban area. Our method takes as input calibrated aerial images and available GIS meta-data. Our computational pipeline computes a per-building 2.5D volumetric reconstruction by exploiting photo-consistency where it is highly sampled among the aerial images. Our building surface graph cut method overcomes errors of occlusion, geometry, and calibration in order to stitch together aerial images and yield a visually coherent texture-mapped result. Our comparisons show similar quality to the manually modeled buildings of Google Earth, and show improvements over naive texture mapping and over space-carving methods.

Deep Fakes & Virtual Humans
|
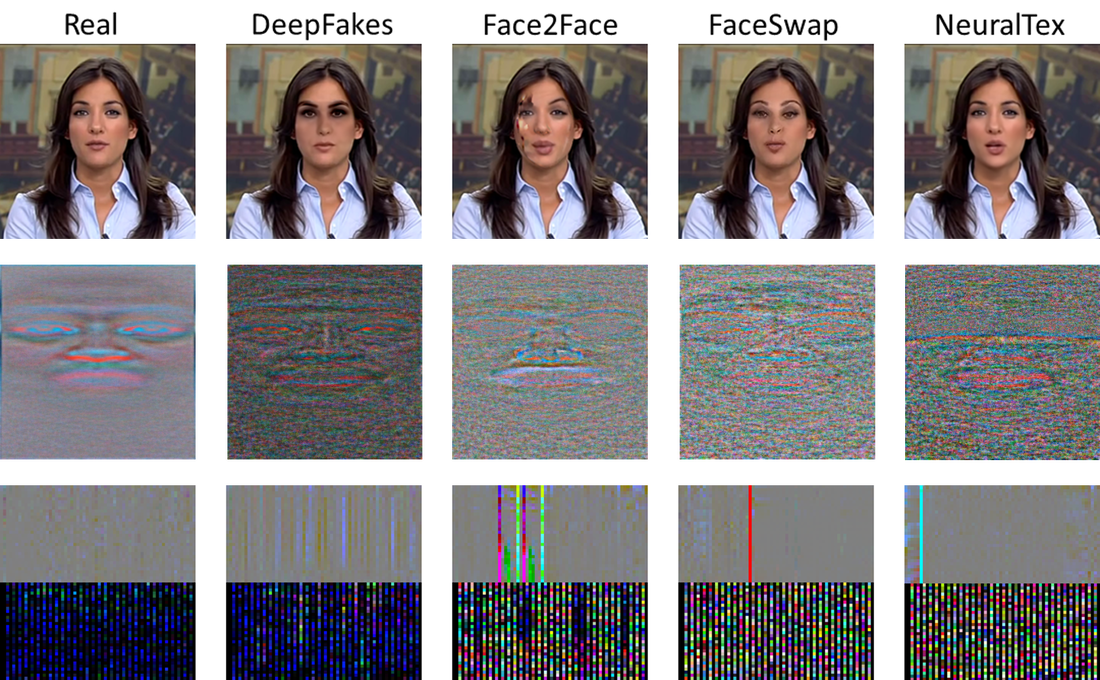
FakeCatcher
We would like to present an approach to detect synthesized content in the domain of portrait videos, as a preventive solution for deep fakes. Our approach exploits biological signals extracted from facial areas based on the observation that these signals are not well-preserved spatially and temporally in synthetic content. We evaluated FakeCatcher both on a state-of-the-art datasets and on our newly introduced Deep Fakes dataset, performing with 96% and 91.07% accuracy respectively. |
|
|
Deep Fake Source Detection
We propose an approach not only to separate deep fakes from real videos, but also to discover the specific generative model behind a deep fake. Pure deep learning based approaches try to classify deep fakes using CNNs where they actually learn the residuals of the generator. We believe that we can reveal these manipulation artifacts by disentangling them with biological signals. Our key observation yields that the spatio-temporal patterns in biological signals can be conceived as a representative projection of residuals. Our results indicate that our approach can detect fake videos with 97.29% accuracy, and the source model with 93.39% accuracy. |
|
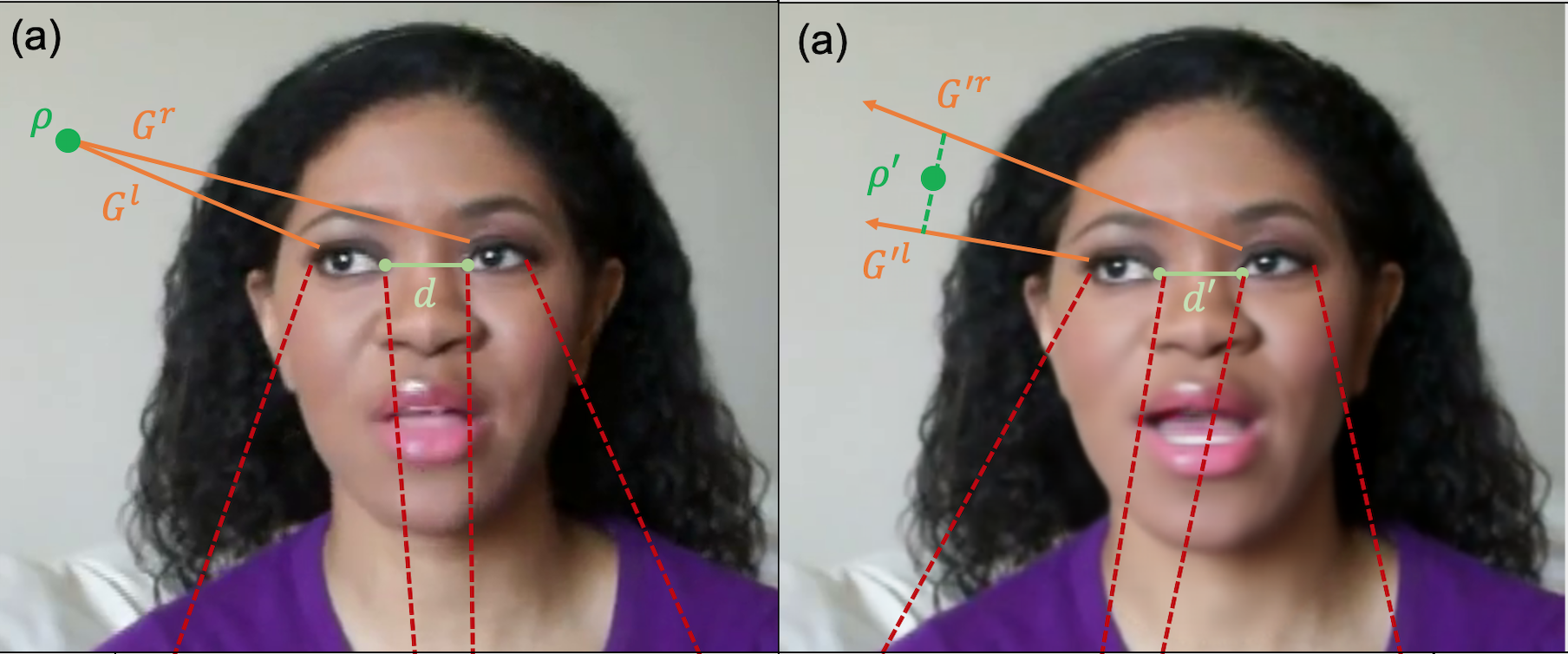
Eye & Gaze Based Deep Fake Detection
In this paper, we first propose several prominent eye and gaze features that deep fakes exhibit differently. Second, we compile those features into signatures and analyze and compare those of real and fake videos, formulating geometric, visual, metric, temporal, and spectral variations. Third, we generalize this formulation to the deep fake detection problem by a deep neural network, to classify any video in the wild as fake or real. We evaluate our approach on several deep fake datasets, achieving 92.48% accuracy on FaceForensics++, 80.0% on Deep Fakes (in the wild), 88.35% on CelebDF, and 99.27% on DeeperForensics datasets. |
|

|
Multi-Source Face Synthesis
We propose an approach to create novel faces from different face regions of multiple sources, by learning compositions and styles simultaneously. Our approach not only combines uncorrelated regions from multiple faces into a coherent semantic mask, but also generates mask-aware high quality reconstructions of non-existing faces. We qualitatively and quantitatively compare against state-of-the-art single source sequential face generation approaches, for visual quality, image diversity, coherence and realism, and expressive power. By altering input images and regions, our approach aids interactive synthesis, mix & match tasks, and edit propagation, without the dependency on given masks. |
|
Machine Learning for VR
Current software and hardware solutions utilized in virtual and augmented reality headsets lack understanding human behavior in VR. We first apply classical machine learning methods to deduct several behavioral generalizations from human track data in VR, which can be used in refining hardware specifications for generalizability. Second, we build several deep learning models for classification, segmentation, and prediction of such human-dependent data, in order to improve essential technologies such as eye tracking and foveated rendering |

|
